Shuffle Write Failing With File Not Found Exception
GUIDE TO SPARK EXECUTION
Fetch Failed Exception in Apache Spark: Decrypting the most common causes
Most Spark developers spend considerable time in troubleshooting the Fetch Failed Exceptions observed during shuffle operations. This story would serve you the most common causes of a Fetch Failed Exception and would reveal the results of a recent poll conducted on the Exception.
![]()
Shuffle operations are the backbone of almost all Spark Jobs that are aimed at data aggregation, joins, or data restructuring. During a shuffle operation, the data is shuffled across various nodes of the cluster via a two-step process:
a) Shuffle Write: Shuffle map tasks write the data to be shuff l ed in a disk file, the data is arranged in the file according to shuffle reduce tasks. Bunch of shuffle data corresponding to a shuffle reduce task written by a shuffle map task is called a shuffle block. Further, each of the shuffle map tasks informs the driver about the written shuffle data.
b) Shuffle Read: Shuffle reduce tasks queries the driver about the locations of their shuffle blocks. Then these tasks establish connections with the executors hosting their shuffle blocks and start fetching the required shuffle blocks. Once a block is fetched, it is available for further computation in the reduce task.
To know more about the shuffle process, you can refer to my earlier story titled: Revealing Apache Spark Shuffling Magic.
The two-step process of a shuffle although sounds simple, but is operationally intensive as it involves data sorting, disk writes/reads, and network transfers. Therefore, there is always a question mark on the reliability of a shuffle operation, and the evidence of this unreliability is the commonly encountered 'FetchFailed Exception' during the shuffle operation. Most Spark developers spend considerable time in troubleshooting this widely encountered exception. First, they try to find out the root cause of the exception, and then accordingly put the right fix for the same.
A Fetch Failed Exception, reported in a shuffle reduce task, indicates the failure in reading of one or more shuffle blocks from the hosting executors. Debugging a FetchFailed Exception is quite challenging since it can occur due to multiple reasons. Finding and knowing the right reason is very important because this would help you in putting the right fix to overcome the Exception.
Troubleshooting hundreds of Spark Jobs in recent time has realized me that Fetch Failed Exception mainly comes due to the following reasons:
- Out of Heap memory on Executors
- Low Memory Overhead on Executors
- Shuffle block greater than 2 GB
- Network TimeOut.
To understand the frequency of these reasons, I also conducted a poll recently on the most followed LinkedIn group on Spark, Apache Spark. To my surprise, quite a lot of people participated in the poll and submitted their opinion which kind of further establishes the fact that people frequently encounter this exception in their Spark Jobs. Here are the results of the poll:
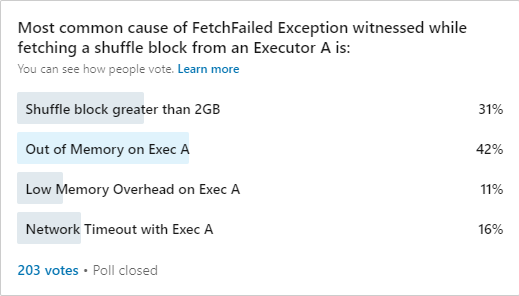
According to the poll results, 'Out of Heap memory on a Executor' and the 'Shuffle block greater than 2 GB' are the most voted reasons. These are then followed by 'Network Timeout' and 'Low memory overhead on a Executor'.
Let's understand each of these reasons in detail:
'Out of Heap memory on an Executor': This reason indicates that the Fetch Failed Exception has come because an Executor hosting the corresponding shuffle blocks has crashed due to Java 'Out of memory' error. 'Out of memory error' could come when there is a shortage of heap space on the executor or Garbage collector of the Executor is wasting more time on garbage collection as compared to real useful work.
To correlate this reason, you need to check the hosting executor details (hostname/IP Address/Port) mentioned in a Fetch Failed Exception. Once you get the executor details, you could notice the following task failures against the hosting executors:
- 'ExecutorLostFailure' due to Exit code 143
- 'ExecutorLostFailure' due to Executor Heartbeat timed out.
These task failures against the hosting executors indicate that the executor hosting the shuffle blocks got killed due to Java 'Out of memory' error. Also, one could explicitly confirm the error in the executor container logs. Since the hosting executor got killed, the hosted shuffle blocks could not be fetched and therefore could result in Fetch Failed Exceptions in one or more shuffle reduce tasks.
As per the poll results, this reason has got the highest vote percentage. I also witnessed a greater proportion of this reason in my work.
'Low memory overhead on an Executor': This reason indicates that a Fetch Failed Exception has come because an Executor hosting the corresponding shuffle blocks has crashed due to 'Low memory overhead'. 'Low memory overhead' error comes when an executor physical RAM footprint crosses the designated physical memory limits. This scenario could happen when executor heap memory is heavily utilized plus there is a good demand for off-heap memory too.
To correlate this reason, you need to check the hosting executor details (hostname/IP Address/Port) mentioned in the Fetch Failed Exception. Once you get the executor details, you could notice the following task failure against the hosting executors:
- 'ExecutorLostFailure, # GB of # GB physical memory used. Consider boosting the spark.yarn.executor.Overhead'
The above task failure against a hosting executor indicates that the executor hosting the shuffle blocks got killed due to the over usage of designated physical memory limits. Again, since the hosting executor got killed, the hosted shuffle blocks could not be fetched and therefore could result in Fetch Failed Exceptions in one or more shuffle reduce tasks.
As per the poll results, this reason has got the lowest vote percentage. But, I have witnessed a greater proportion of this reason too. Infact, the proportion is similar to 'Out of memory on an Executor' reason.
'Shuffle block greater than 2 GB': Fetch Failed Exception mentioning 'Too Large Frame', 'Frame size exceeding' or 'size exceeding Integer.MaxValue' as the error cause indicates that the corresponding Shuffle reduce task was trying to fetch a shuffle block greater than 2 GB. This mainly comes due to the limit of Integer.MaxValue(2GB) on the data structure abstraction (ByteBuffer) being used to store a shuffle block in the memory.
However, starting Spark release 2.4, this particular cause is largely addressed.
As per the poll results, this reason has got the second highest vote percentage. But, I have rarely witnessed Fetch Failed due to this in my work.
'Network Timeout': Fetching of Shuffle blocks is generally retried for a configurable number of times (spark.shuffle.io.maxRetries) at configurable intervals (spark.shuffle.io.retryWait). When all the retires are exhausted while fetching a shuffle block from its hosting executor, a Fetch Failed Exception is raised in the shuffle reduce task. These Fetch Failed Exceptions are usually categorized in the 'Network Timeout' category.
Such Fetch Failed exceptions are difficult to correlate. Further, these exceptions may arise due to network issues, or when the executors hosting the corresponding shuffle blocks are getting overwhelmed.
As per the poll results, this reason has got the third highest vote percentage. I too have witnessed this cause frequently.
I hope, after reading the story, you must now be having a fair idea about the various causes of Fetch Failed Exceptions. I am planning to cover the possible fixes against each cause in a different story. In case, you are looking for a fix urgently against a Fetch Failed Exception, you could drop a message.
Lastly, I would like to thank all the people who participated in the poll and submitted their opinions.
In case of feedback or queries on this story, do write in the comments section. I hope, you would find it useful. Here is the link to other comprehensive stories on Apache Spark posted by me.
Shuffle Write Failing With File Not Found Exception
Source: https://towardsdatascience.com/fetch-failed-exception-in-apache-spark-decrypting-the-most-common-causes-b8dff21075c
0 Response to "Shuffle Write Failing With File Not Found Exception"
Post a Comment